Т‑банк завёз открытый свежачок: T-pro 2.0 32B русскоязычная модель на базе Qwen3‑32B. Модель прогнали через 40 млрд токенов претрейна (треть из них reasoning), потом долили ~500к SFT‑промптов и ещё 100к пар для preference‑tuning, так что она заметно лучше думает на русском. На публичных бенчах получаем +5‑10 процентных пунктов к голому Qwen3‑32B: ruMMLU 79 % (+5), Ru‑Arena‑Hard 87,6 % (+4,4), MERA 66 % (+7,6) — среди локальных языковых моделей это один из лучших результатов прямо сейчас. Детали тренировки обещают завтра, на Turbo ML Conf. Модель — гибридный ризонер, с 32к контекста, которые растягиваются до 131к при помощи YaRN. Авторы опубликовали не просто чекпоинт — релизнули сразу и официальную fp8 версию плюс пачку GGUF, так что модель могут использовать обычные юзеры без плясок с бубном. Натренировали и Eagle драфт модель, которая даёт до 60% прироста в скорости инференса при маленьких батчах — скорость растёт с 69 токенов в секунду до 110. Лицензия — Apache 2.0, так что можно спокойно юзать в любых целях, в том числе коммерческих. Веса
NeuroVesti
Т‑банк завёз открытый свежачок: T-pro 2.0
32B русскоязычная модель на базе Qwen3‑32B. Модель прогнали через 40 млрд токенов претрейна (треть из них reasoning), потом долили ~500к SFT‑промптов и ещё 100к пар для preference‑tuning, так что она заметно лучше думает на русском.
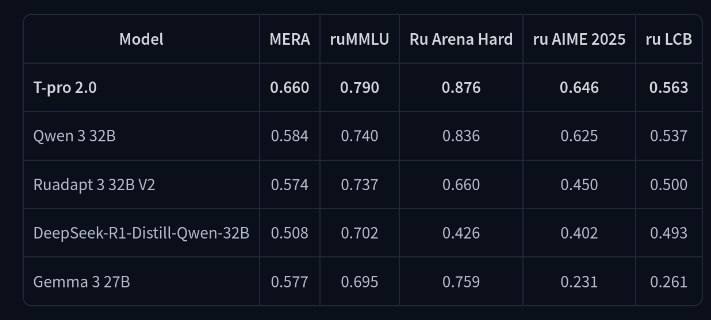
На публичных бенчах получаем +5‑10 процентных пунктов к голому Qwen3‑32B: ruMMLU 79 % (+5), Ru‑Arena‑Hard 87,6 % (+4,4), MERA 66 % (+7,6) — среди локальных языковых моделей это один из лучших результатов прямо сейчас. Детали тренировки обещают завтра, на Turbo ML Conf.
Модель — гибридный ризонер, с 32к контекста, которые растягиваются до 131к при помощи YaRN. Авторы опубликовали не просто чекпоинт — релизнули сразу и официальную fp8 версию плюс пачку GGUF, так что модель могут использовать обычные юзеры без плясок с бубном. Натренировали и Eagle драфт модель, которая даёт до 60% прироста в скорости инференса при маленьких батчах — скорость растёт с 69 токенов в секунду до 110.
Лицензия — Apache 2.0, так что можно спокойно юзать в любых целях, в том числе коммерческих.
Веса
Т‑банк завёз открытый свежачок: T-pro 2.0
32B русскоязычная модель на базе Qwen3‑32B. Модель прогнали через 40 млрд токенов претрейна (треть из них reasoning), потом долили ~500к SFT‑промптов и ещё 100к пар для preference‑tuning, так что она заметно лучше думает на русском.
На публичных бенчах получаем +5‑10 процентных пунктов к голому Qwen3‑32B: ruMMLU 79 % (+5), Ru‑Arena‑Hard 87,6 % (+4,4), MERA 66 % (+7,6) — среди локальных языковых моделей это один из лучших результатов прямо сейчас. Детали тренировки обещают завтра, на Turbo ML Conf.
Модель — гибридный ризонер, с 32к контекста, которые растягиваются до 131к при помощи YaRN. Авторы опубликовали не просто чекпоинт — релизнули сразу и официальную fp8 версию плюс пачку GGUF, так что модель могут использовать обычные юзеры без плясок с бубном. Натренировали и Eagle драфт модель, которая даёт до 60% прироста в скорости инференса при маленьких батчах — скорость растёт с 69 токенов в секунду до 110.
Лицензия — Apache 2.0, так что можно спокойно юзать в любых целях, в том числе коммерческих.
Веса
Дата публикации: 18.07.2025 15:00