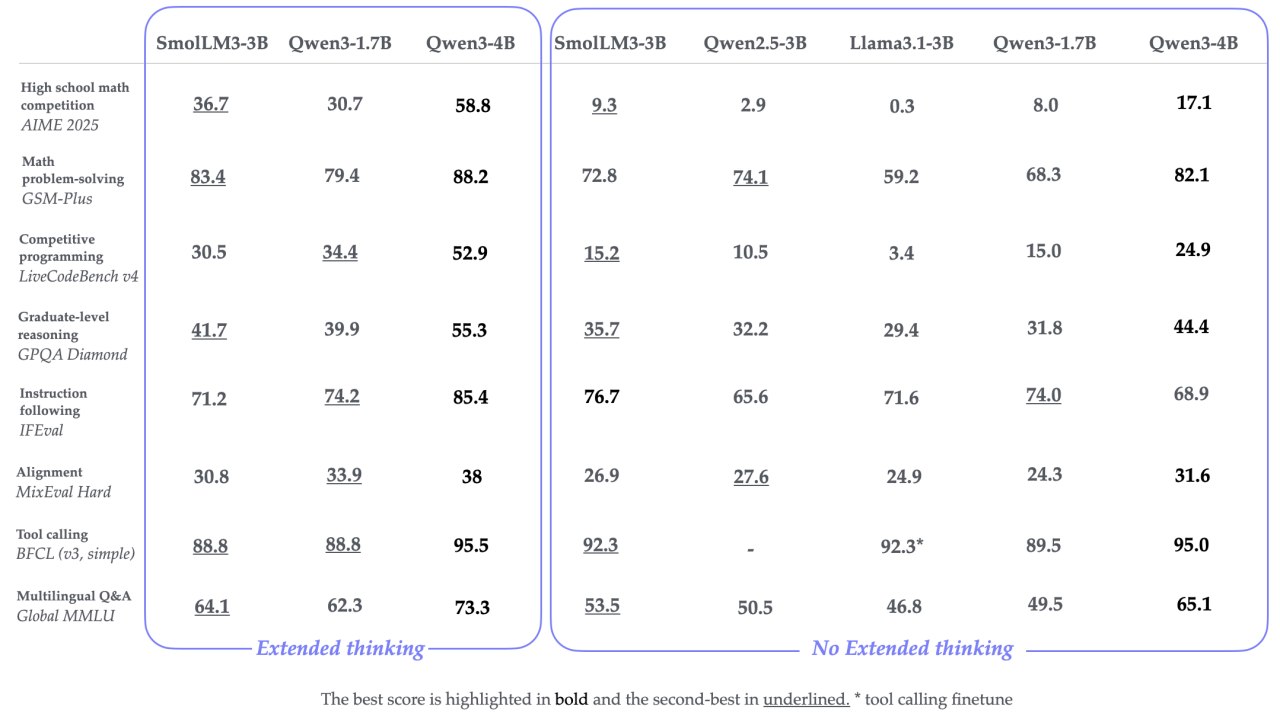
SmolLM 3 — полностью открытая 3B модель от Huggingface Это самая сильная 3B модель — она опережает Llama-3-3B и Qwen 2.5-3B, но отстаёт от более крупных 4B Qwen 3 и Gemma 3. Модель — гибридный ризонер, как новые Claude или Qwen 3. Самое ценное в релизе — блогпост с деталями тренировки и опубликованные конфиги, так что воспроизвести модель будет крайне просто. Модель тренировали 24 дня на 384 GPU H100 (220к часов) по трёхстадийной схеме: сначала Web + Code + Math, затем постепенно повышали долю кода и математики. После основного претрейна добавили mid-training для расширения контекста, затем mid-training на ризонинг. К сожалению, ризонингу модель учили исключительно на готовых ризонинг трейсах, RL тут совсем не использовался. Посттрейнили с SFT на 1,8B токенов: 1B без reasoning-трейсов и 0,8B с /think, данные взяли из 22 открытых датасетов. Тренировали 4 эпохи (~8B токенов) с BFD-packing и маскировали лосс на пользовательских репликах, чтобы не штрафовать system-промпты и tool-calls. Затем модель тюнили с Anchored Preference Optimization: реальные пары из Tulu 3 дополнили синтетическими chosen vs rejected ответами Qwen3-32B/0.6B, покрыв оба режима /think и /no_think. После этого несколько чекпоинтов полученных при тюне с APO смешали в одну, а уже её смерджили с мидтрейн-чекпоинтом — так сохранили 128k контекст, без просадки на математике и коде. Иметь такие открытые рецепты в общем доступе крайне важно — они служат бейзлайном, поверх которого можно последовательно улучшать любой этап пайплайна. Без таких рецептов, делать ресёрч по претрейну гораздо сложнее. Блогпост Веса Конфиги для тренировки с помощью nanotron
NeuroVesti
SmolLM 3 — полностью открытая 3B модель от Huggingface
Это самая сильная 3B модель — она опережает Llama-3-3B и Qwen 2.5-3B, но отстаёт от более крупных 4B Qwen 3 и Gemma 3. Модель — гибридный ризонер, как новые Claude или Qwen 3.
Самое ценное в релизе — блогпост с деталями тренировки и опубликованные конфиги, так что воспроизвести модель будет крайне просто. Модель тренировали 24 дня на 384 GPU H100 (220к часов) по трёхстадийной схеме: сначала Web + Code + Math, затем постепенно повышали долю кода и математики. После основного претрейна добавили mid-training для расширения контекста, затем mid-training на ризонинг. К сожалению, ризонингу модель учили исключительно на готовых ризонинг трейсах, RL тут совсем не использовался.
Посттрейнили с SFT на 1,8B токенов: 1B без reasoning-трейсов и 0,8B с /think, данные взяли из 22 открытых датасетов. Тренировали 4 эпохи (~8B токенов) с BFD-packing и маскировали лосс на пользовательских репликах, чтобы не штрафовать system-промпты и tool-calls. Затем модель тюнили с Anchored Preference Optimization: реальные пары из Tulu 3 дополнили синтетическими chosen vs rejected ответами Qwen3-32B/0.6B, покрыв оба режима /think и /no_think. После этого несколько чекпоинтов полученных при тюне с APO смешали в одну, а уже её смерджили с мидтрейн-чекпоинтом — так сохранили 128k контекст, без просадки на математике и коде.
Иметь такие открытые рецепты в общем доступе крайне важно — они служат бейзлайном, поверх которого можно последовательно улучшать любой этап пайплайна. Без таких рецептов, делать ресёрч по претрейну гораздо сложнее.
Блогпост
Веса
Конфиги для тренировки с помощью nanotron
SmolLM 3 — полностью открытая 3B модель от Huggingface
Это самая сильная 3B модель — она опережает Llama-3-3B и Qwen 2.5-3B, но отстаёт от более крупных 4B Qwen 3 и Gemma 3. Модель — гибридный ризонер, как новые Claude или Qwen 3.
Самое ценное в релизе — блогпост с деталями тренировки и опубликованные конфиги, так что воспроизвести модель будет крайне просто. Модель тренировали 24 дня на 384 GPU H100 (220к часов) по трёхстадийной схеме: сначала Web + Code + Math, затем постепенно повышали долю кода и математики. После основного претрейна добавили mid-training для расширения контекста, затем mid-training на ризонинг. К сожалению, ризонингу модель учили исключительно на готовых ризонинг трейсах, RL тут совсем не использовался.
Посттрейнили с SFT на 1,8B токенов: 1B без reasoning-трейсов и 0,8B с /think, данные взяли из 22 открытых датасетов. Тренировали 4 эпохи (~8B токенов) с BFD-packing и маскировали лосс на пользовательских репликах, чтобы не штрафовать system-промпты и tool-calls. Затем модель тюнили с Anchored Preference Optimization: реальные пары из Tulu 3 дополнили синтетическими chosen vs rejected ответами Qwen3-32B/0.6B, покрыв оба режима /think и /no_think. После этого несколько чекпоинтов полученных при тюне с APO смешали в одну, а уже её смерджили с мидтрейн-чекпоинтом — так сохранили 128k контекст, без просадки на математике и коде.
Иметь такие открытые рецепты в общем доступе крайне важно — они служат бейзлайном, поверх которого можно последовательно улучшать любой этап пайплайна. Без таких рецептов, делать ресёрч по претрейну гораздо сложнее.
Блогпост
Веса
Конфиги для тренировки с помощью nanotron
Дата публикации: 08.07.2025 19:09