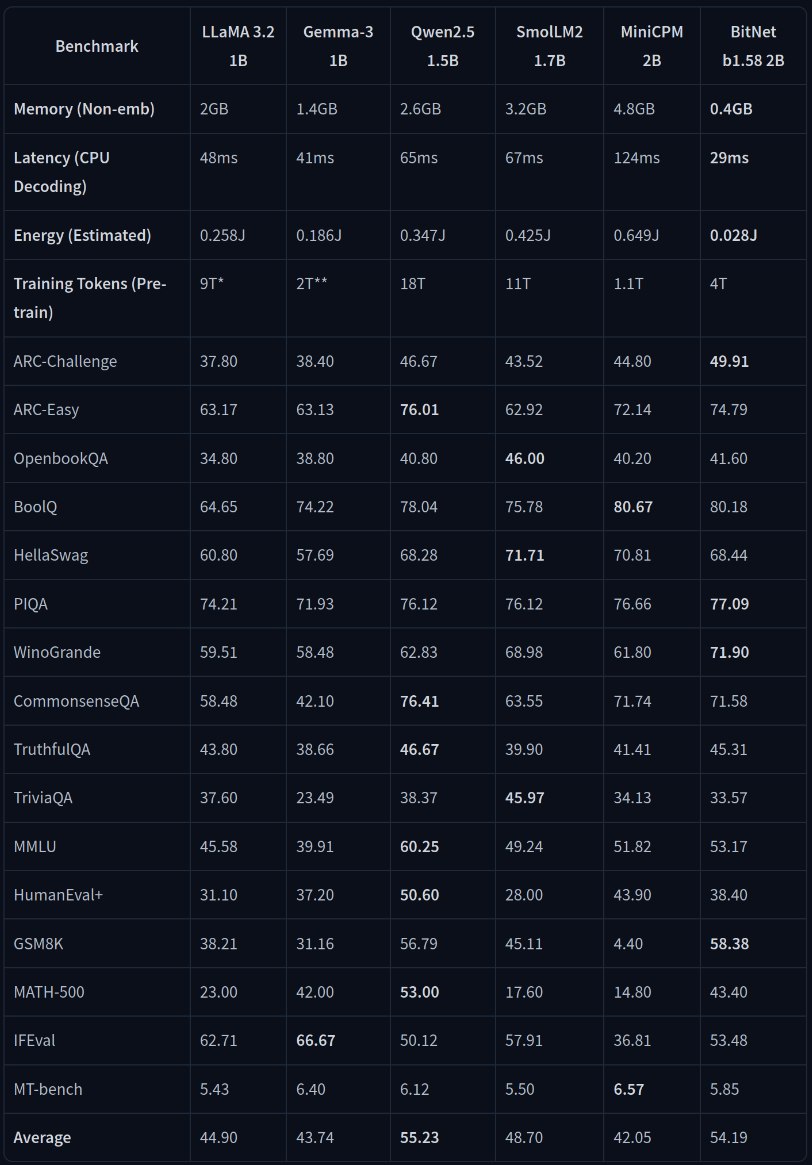
Microsoft выпустила веса BitNet модели (спустя год) Я уже писал о BitNet — методе тренировки моделей сразу квантизированными до 1.58 бит, но тогда авторы выложили лишь пару сниппетов кода, без весов. Их новая 2B модель примерно равна Qwen 2.5 1.5B на бенчах, но в два раза быстрее и использует в 12 раз меньше энергии. Натренировали её всего на 4 триллионах токенов, что хоть и мало для моделей побольше, но нормально в такой весовой категории — ту же Gemma 3 1B натренировали на лишь двух триллионах токенов, а 4B на 4. Но есть здесь и ложка дёгтя — так как модель от Microsoft, то вероятно что модели тренировали на датасетах от Phi моделей, у которых крайне скверная репутация. Как модель себя ведёт на самом деле — покажет лишь опыт использования. Если хотите попробовать — для инференса рекомендуют использовать майкрософтовский bitnet.cpp, остальной софт вроде BitNet модели не поддерживает. Веса
NeuroVesti
Microsoft выпустила веса BitNet модели (спустя год)
Я уже писал о BitNet — методе тренировки моделей сразу квантизированными до 1.58 бит, но тогда авторы выложили лишь пару сниппетов кода, без весов. Их новая 2B модель примерно равна Qwen 2.5 1.5B на бенчах, но в два раза быстрее и использует в 12 раз меньше энергии. Натренировали её всего на 4 триллионах токенов, что хоть и мало для моделей побольше, но нормально в такой весовой категории — ту же Gemma 3 1B натренировали на лишь двух триллионах токенов, а 4B на 4.
Но есть здесь и ложка дёгтя — так как модель от Microsoft, то вероятно что модели тренировали на датасетах от Phi моделей, у которых крайне скверная репутация. Как модель себя ведёт на самом деле — покажет лишь опыт использования. Если хотите попробовать — для инференса рекомендуют использовать майкрософтовский bitnet.cpp, остальной софт вроде BitNet модели не поддерживает.
Веса
Microsoft выпустила веса BitNet модели (спустя год)
Я уже писал о BitNet — методе тренировки моделей сразу квантизированными до 1.58 бит, но тогда авторы выложили лишь пару сниппетов кода, без весов. Их новая 2B модель примерно равна Qwen 2.5 1.5B на бенчах, но в два раза быстрее и использует в 12 раз меньше энергии. Натренировали её всего на 4 триллионах токенов, что хоть и мало для моделей побольше, но нормально в такой весовой категории — ту же Gemma 3 1B натренировали на лишь двух триллионах токенов, а 4B на 4.
Но есть здесь и ложка дёгтя — так как модель от Microsoft, то вероятно что модели тренировали на датасетах от Phi моделей, у которых крайне скверная репутация. Как модель себя ведёт на самом деле — покажет лишь опыт использования. Если хотите попробовать — для инференса рекомендуют использовать майкрософтовский bitnet.cpp, остальной софт вроде BitNet модели не поддерживает.
Веса
Дата публикации: 15.04.2025 17:44