Mechanistic permutability: Match across layers В современных нейронках одна из ключевых проблем интерпретируемости — полисемантичность, когда отдельные нейроны энкодят сразу несколько разных понятий. Sparse autoencoders (SAE) решают эту проблему, обучаясь реконструировать скрытые состояния модели при условии активации лишь небольшого числа нейронов. Метод SAE Match развивает эту концепцию, предлагая data-free технику сопоставления признаков между различными слоями нейросети — исследователи из T-Bank AI Research могут анализировать, как трансформируются признаки при прохождении через модель, не прогоняя через нее новые данные. Технически SAE Match работает через сопоставление параметров автоэнкодеров, обученных на разных слоях. Ключевая инновация — техника parameter folding, которая интегрирует пороговые значения активации функции JumpReLU в веса энкодера и декодера. Это позволяет учитывать различия в масштабах скрытых состояний между слоями и находить перестановочные матрицы, которые оптимально выравнивают семантически схожие признаки. Авторы формулируют задачу как поиск матрицы перестановок, минимизирующей среднеквадратичную ошибку между параметрами SAE, что математически соответствует максимизации скалярного произведения Фробениуса. Исследователи валидировали свой подход на языковой модели Gemma 2, минимизируя среднеквадратичную ошибку между параметрами SAE для поиска оптимальных перестановочных матриц, которые выравнивают семантически похожие признаки. Эксперименты показали, что сопоставление признаков работает оптимально в средних и поздних слоях (после 10-го), с сохранением семантической целостности на протяжении примерно пяти последовательных слоев. Это позволяет отслеживать изменения концептов по мере распространения информации через архитектуру сети. У метода есть практическое применение и в прунинге — авторы успешно аппроксимируют hidden state при пропуске слоев, через операцию кодирования-перестановки-декодирования. Это фактически позволяет оптимизировать модель без существенного снижения качества. Методология оценки результатов тоже интересная — авторы использовали внешнюю языковую модель для анализа семантического сходства сопоставленных признаков, классифицируя их как "SAME", "MAYBE" или "DIFFERENT". Это позволило объективно оценить качество сопоставления и подтвердить, что метод действительно работает. Статья едет на ICLR 2025 в конце месяца, что показывает её значимость. Пейпер
NeuroVesti
Mechanistic permutability: Match across layers
В современных нейронках одна из ключевых проблем интерпретируемости — полисемантичность, когда отдельные нейроны энкодят сразу несколько разных понятий. Sparse autoencoders (SAE) решают эту проблему, обучаясь реконструировать скрытые состояния модели при условии активации лишь небольшого числа нейронов. Метод SAE Match развивает эту концепцию, предлагая data-free технику сопоставления признаков между различными слоями нейросети — исследователи из T-Bank AI Research могут анализировать, как трансформируются признаки при прохождении через модель, не прогоняя через нее новые данные.
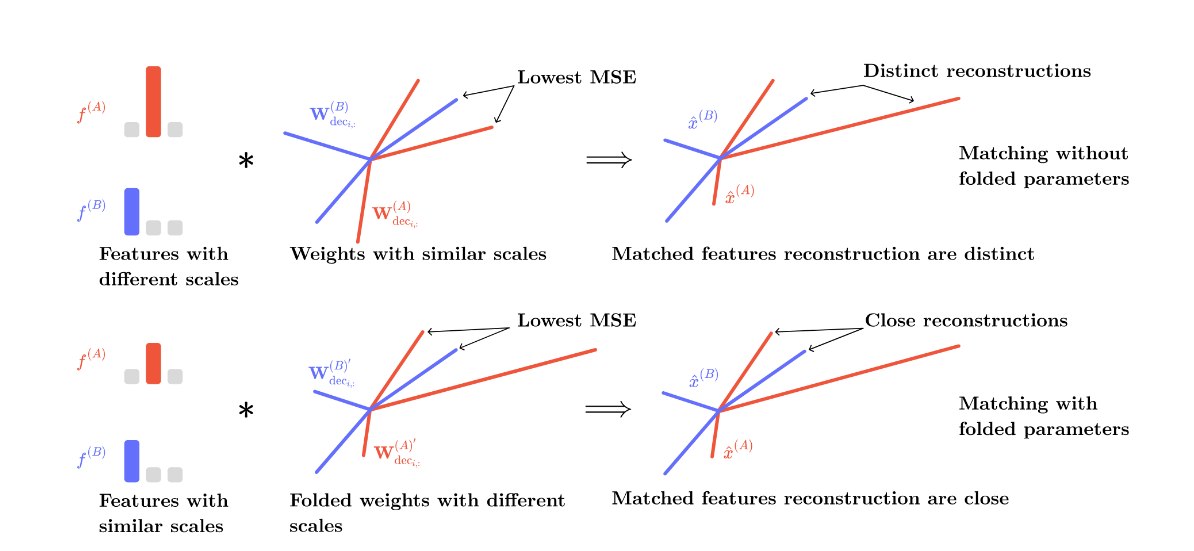
Технически SAE Match работает через сопоставление параметров автоэнкодеров, обученных на разных слоях. Ключевая инновация — техника parameter folding, которая интегрирует пороговые значения активации функции JumpReLU в веса энкодера и декодера. Это позволяет учитывать различия в масштабах скрытых состояний между слоями и находить перестановочные матрицы, которые оптимально выравнивают семантически схожие признаки. Авторы формулируют задачу как поиск матрицы перестановок, минимизирующей среднеквадратичную ошибку между параметрами SAE, что математически соответствует максимизации скалярного произведения Фробениуса.
Исследователи валидировали свой подход на языковой модели Gemma 2, минимизируя среднеквадратичную ошибку между параметрами SAE для поиска оптимальных перестановочных матриц, которые выравнивают семантически похожие признаки. Эксперименты показали, что сопоставление признаков работает оптимально в средних и поздних слоях (после 10-го), с сохранением семантической целостности на протяжении примерно пяти последовательных слоев. Это позволяет отслеживать изменения концептов по мере распространения информации через архитектуру сети.
У метода есть практическое применение и в прунинге — авторы успешно аппроксимируют hidden state при пропуске слоев, через операцию кодирования-перестановки-декодирования. Это фактически позволяет оптимизировать модель без существенного снижения качества.
Методология оценки результатов тоже интересная — авторы использовали внешнюю языковую модель для анализа семантического сходства сопоставленных признаков, классифицируя их как "SAME", "MAYBE" или "DIFFERENT". Это позволило объективно оценить качество сопоставления и подтвердить, что метод действительно работает. Статья едет на ICLR 2025 в конце месяца, что показывает её значимость.
Пейпер
Mechanistic permutability: Match across layers
В современных нейронках одна из ключевых проблем интерпретируемости — полисемантичность, когда отдельные нейроны энкодят сразу несколько разных понятий. Sparse autoencoders (SAE) решают эту проблему, обучаясь реконструировать скрытые состояния модели при условии активации лишь небольшого числа нейронов. Метод SAE Match развивает эту концепцию, предлагая data-free технику сопоставления признаков между различными слоями нейросети — исследователи из T-Bank AI Research могут анализировать, как трансформируются признаки при прохождении через модель, не прогоняя через нее новые данные.
Технически SAE Match работает через сопоставление параметров автоэнкодеров, обученных на разных слоях. Ключевая инновация — техника parameter folding, которая интегрирует пороговые значения активации функции JumpReLU в веса энкодера и декодера. Это позволяет учитывать различия в масштабах скрытых состояний между слоями и находить перестановочные матрицы, которые оптимально выравнивают семантически схожие признаки. Авторы формулируют задачу как поиск матрицы перестановок, минимизирующей среднеквадратичную ошибку между параметрами SAE, что математически соответствует максимизации скалярного произведения Фробениуса.
Исследователи валидировали свой подход на языковой модели Gemma 2, минимизируя среднеквадратичную ошибку между параметрами SAE для поиска оптимальных перестановочных матриц, которые выравнивают семантически похожие признаки. Эксперименты показали, что сопоставление признаков работает оптимально в средних и поздних слоях (после 10-го), с сохранением семантической целостности на протяжении примерно пяти последовательных слоев. Это позволяет отслеживать изменения концептов по мере распространения информации через архитектуру сети.
У метода есть практическое применение и в прунинге — авторы успешно аппроксимируют hidden state при пропуске слоев, через операцию кодирования-перестановки-декодирования. Это фактически позволяет оптимизировать модель без существенного снижения качества.
Методология оценки результатов тоже интересная — авторы использовали внешнюю языковую модель для анализа семантического сходства сопоставленных признаков, классифицируя их как "SAME", "MAYBE" или "DIFFERENT". Это позволило объективно оценить качество сопоставления и подтвердить, что метод действительно работает. Статья едет на ICLR 2025 в конце месяца, что показывает её значимость.
Пейпер
Дата публикации: 10.04.2025 11:07