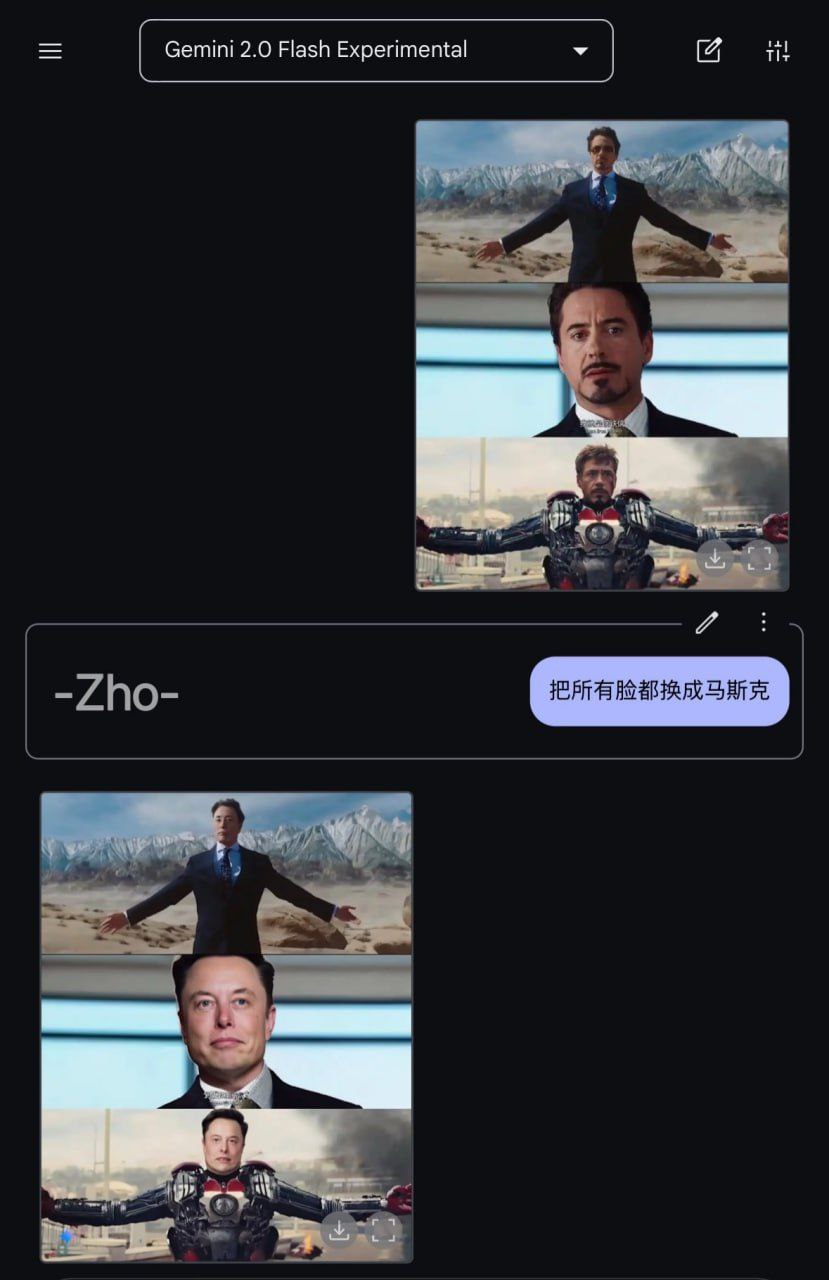
RIP Photoshop (нет) Потестил я мультимодальную Gemini Flash 2.0 (Image Generation) Experimental. Мог бы сказать, что фотошоп в целом больше не нужен, но, блин, эта штука в туории может куда больше, чем мог бы Photoshop. Я совсем не представляю, как можно было бы вручную наложить шоколадный крем на круассаны с первой пикчи. Никакой из доступных из коробки методов не способен был такое провернуть. Через ControlNet или inpainting так не сделаешь, потому что они изменяют детали — круассаны будут чуть другими или по-другому лежать. А здесь мы имеем хирургически точное редактирование картинки одним только текстом. Единственный минус пока - это низкая детализация и низкое разрешение генераций. Другие юзкейсы: - Product photo — раньше нужно было бы тренить LoRA, чтобы получить пикчу №2. Нужно больше фотографий + примерно час работы. - Character sheet design — пикча №3. По одному концепту получаем разворот с трех сторон для моделлеров. Можно было бы погенерить что-то подобное, но здесь мы видим консистентность, которой раньше было сложно добиться моделями из коробки. - Нейрофотосессии — пикча №4. Повторяем лицо по одной фотографии так, словно это LoRA для Flux. - Гайды — пикчи №5,6,7. Может на картинке выделять, куда тыкнуть, рисовать консистентные гайды, как здесь в примере с готовкой. И т.д. Вот она, сила мультимодальных моделей. Все это благодаря тому, что тут генерация изображений и LLM объединены вместе. В отличие от, например Flux или Imagen 3, тут картиночные токены выплевываются напрямую из LLM, без вызова диффузии. За счет этого и достигается более нативное редактирование входных картинок. Но такой метод все же пока уступает диффузии в качестве генерации. Кстати, в Grok такую LLM-генерацию (Aurora) завезли еще в декабре, и ее можно попробовать в Grok3, вот только редактирование там пока отключили. Что-то подобное показывала OpenAI ещё в прошлом году, но так в прод и не завезли (эх Cэма-Сэма). Если Gemini Flash так хорош и дешевле, то что будет с 4o? Попробовать можно в ai studio.



NeuroVesti
RIP Photoshop (нет)
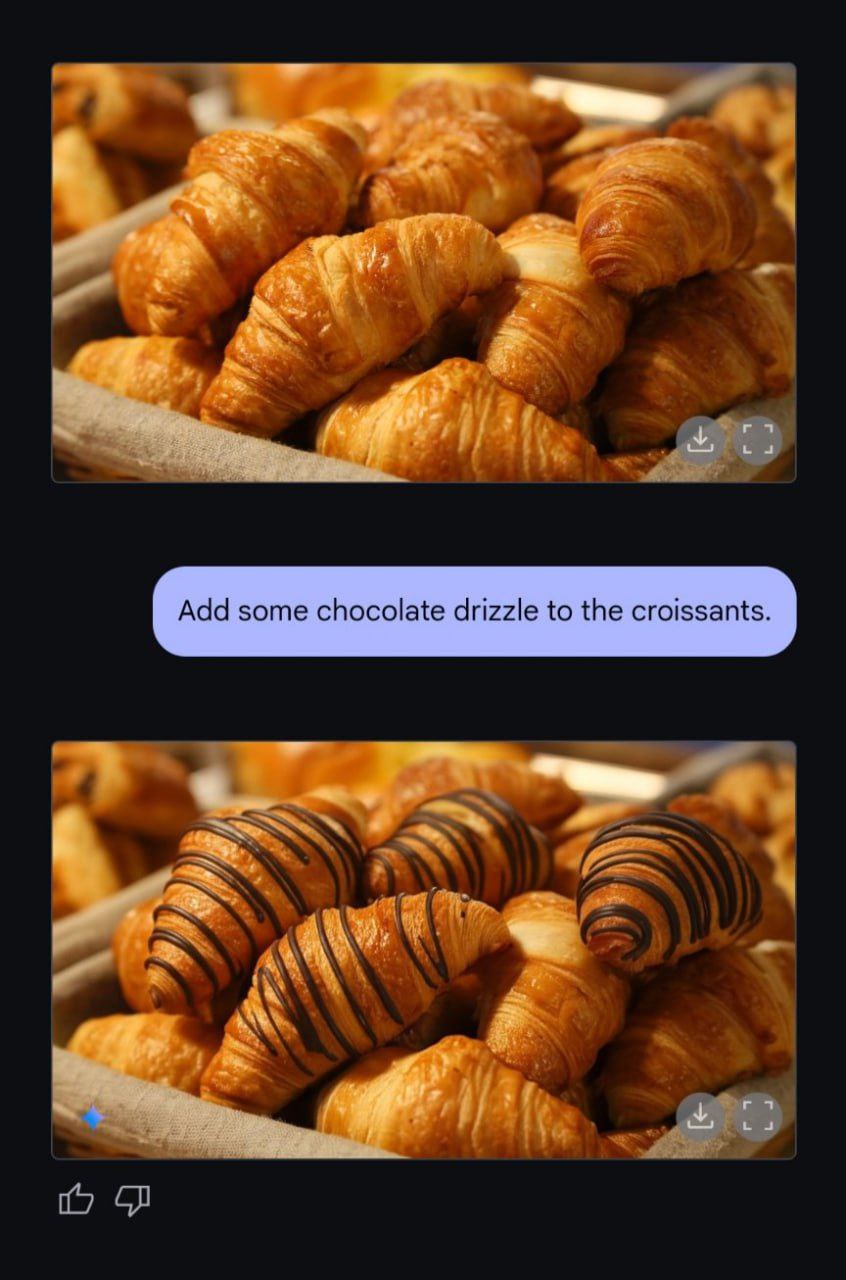
Потестил я мультимодальную Gemini Flash 2.0 (Image Generation) Experimental. Мог бы сказать, что фотошоп в целом больше не нужен, но, блин, эта штука в туории может куда больше, чем мог бы Photoshop. Я совсем не представляю, как можно было бы вручную наложить шоколадный крем на круассаны с первой пикчи.
Никакой из доступных из коробки методов не способен был такое провернуть. Через ControlNet или inpainting так не сделаешь, потому что они изменяют детали — круассаны будут чуть другими или по-другому лежать. А здесь мы имеем хирургически точное редактирование картинки одним только текстом. Единственный минус пока - это низкая детализация и низкое разрешение генераций.
Другие юзкейсы:
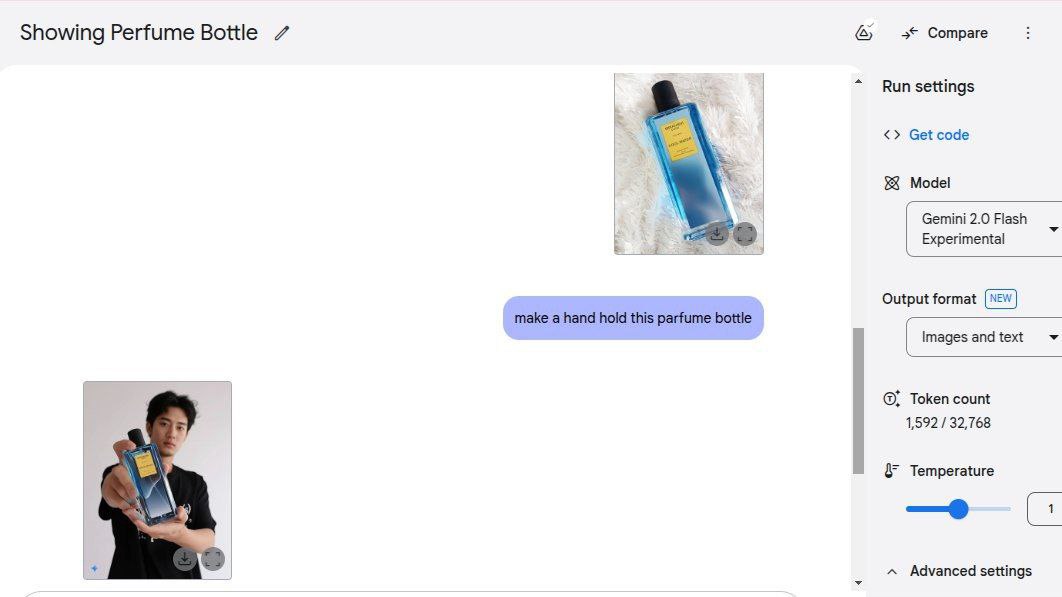
- Product photo — раньше нужно было бы тренить LoRA, чтобы получить пикчу №2. Нужно больше фотографий + примерно час работы.
- Character sheet design — пикча №3. По одному концепту получаем разворот с трех сторон для моделлеров. Можно было бы погенерить что-то подобное, но здесь мы видим консистентность, которой раньше было сложно добиться моделями из коробки.
- Нейрофотосессии — пикча №4. Повторяем лицо по одной фотографии так, словно это LoRA для Flux.
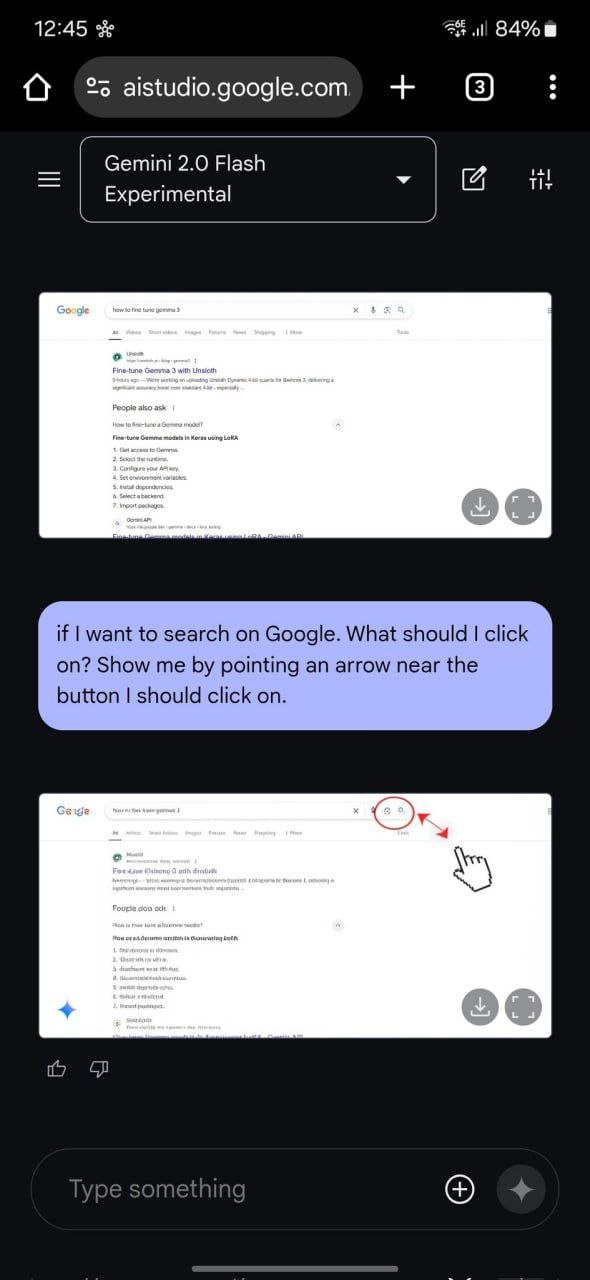
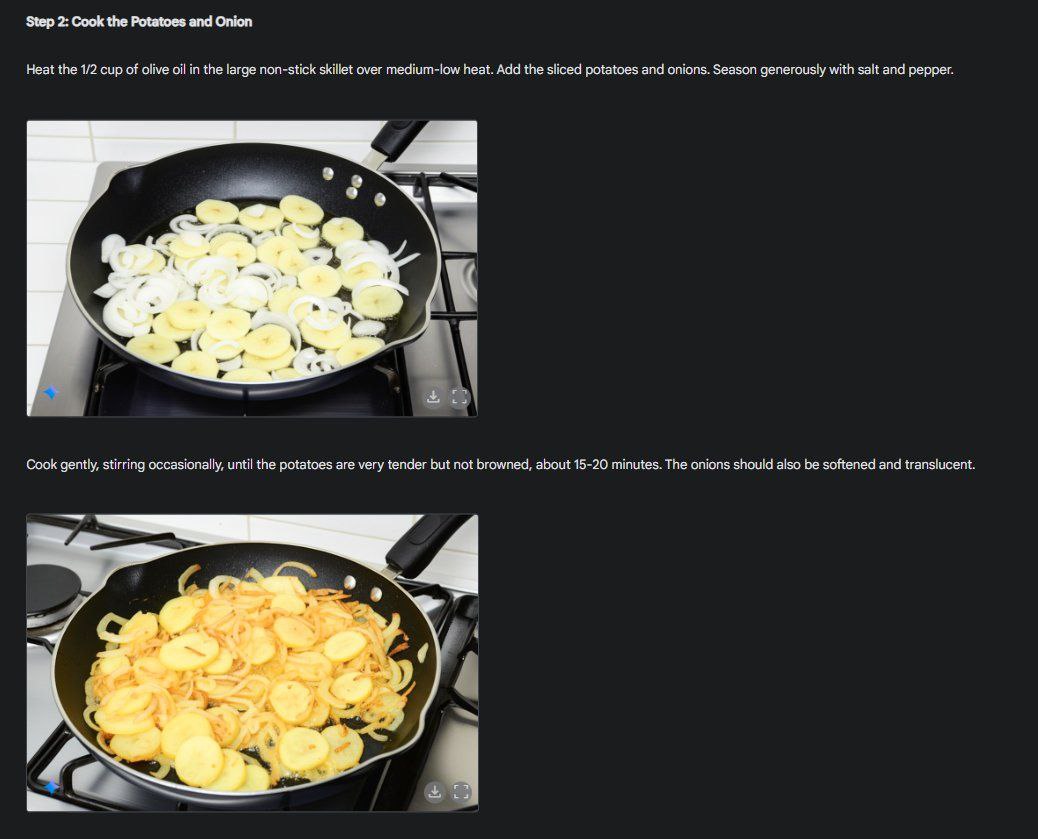
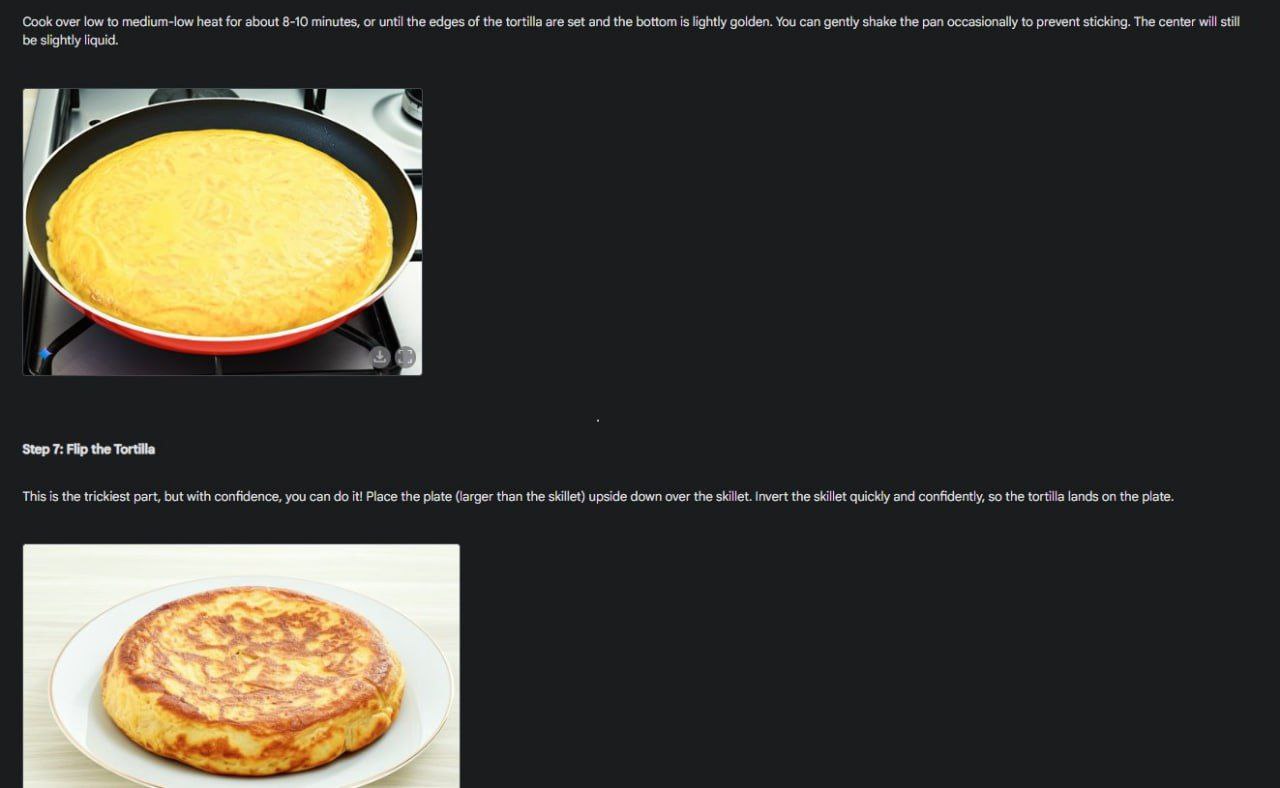
- Гайды — пикчи №5,6,7. Может на картинке выделять, куда тыкнуть, рисовать консистентные гайды, как здесь в примере с готовкой.
И т.д.
Вот она, сила мультимодальных моделей. Все это благодаря тому, что тут генерация изображений и LLM объединены вместе. В отличие от, например Flux или Imagen 3, тут картиночные токены выплевываются напрямую из LLM, без вызова диффузии. За счет этого и достигается более нативное редактирование входных картинок. Но такой метод все же пока уступает диффузии в качестве генерации.
Кстати, в Grok такую LLM-генерацию (Aurora) завезли еще в декабре, и ее можно попробовать в Grok3, вот только редактирование там пока отключили.
Что-то подобное показывала OpenAI ещё в прошлом году, но так в прод и не завезли (эх Cэма-Сэма). Если Gemini Flash так хорош и дешевле, то что будет с 4o?
Попробовать можно в ai studio.
RIP Photoshop (нет)
Потестил я мультимодальную Gemini Flash 2.0 (Image Generation) Experimental. Мог бы сказать, что фотошоп в целом больше не нужен, но, блин, эта штука в туории может куда больше, чем мог бы Photoshop. Я совсем не представляю, как можно было бы вручную наложить шоколадный крем на круассаны с первой пикчи.
Никакой из доступных из коробки методов не способен был такое провернуть. Через ControlNet или inpainting так не сделаешь, потому что они изменяют детали — круассаны будут чуть другими или по-другому лежать. А здесь мы имеем хирургически точное редактирование картинки одним только текстом. Единственный минус пока - это низкая детализация и низкое разрешение генераций.
Другие юзкейсы:
- Product photo — раньше нужно было бы тренить LoRA, чтобы получить пикчу №2. Нужно больше фотографий + примерно час работы.
- Character sheet design — пикча №3. По одному концепту получаем разворот с трех сторон для моделлеров. Можно было бы погенерить что-то подобное, но здесь мы видим консистентность, которой раньше было сложно добиться моделями из коробки.
- Нейрофотосессии — пикча №4. Повторяем лицо по одной фотографии так, словно это LoRA для Flux.
- Гайды — пикчи №5,6,7. Может на картинке выделять, куда тыкнуть, рисовать консистентные гайды, как здесь в примере с готовкой.
И т.д.
Вот она, сила мультимодальных моделей. Все это благодаря тому, что тут генерация изображений и LLM объединены вместе. В отличие от, например Flux или Imagen 3, тут картиночные токены выплевываются напрямую из LLM, без вызова диффузии. За счет этого и достигается более нативное редактирование входных картинок. Но такой метод все же пока уступает диффузии в качестве генерации.
Кстати, в Grok такую LLM-генерацию (Aurora) завезли еще в декабре, и ее можно попробовать в Grok3, вот только редактирование там пока отключили.
Что-то подобное показывала OpenAI ещё в прошлом году, но так в прод и не завезли (эх Cэма-Сэма). Если Gemini Flash так хорош и дешевле, то что будет с 4o?
Попробовать можно в ai studio.
Дата публикации: 16.03.2025 14:40