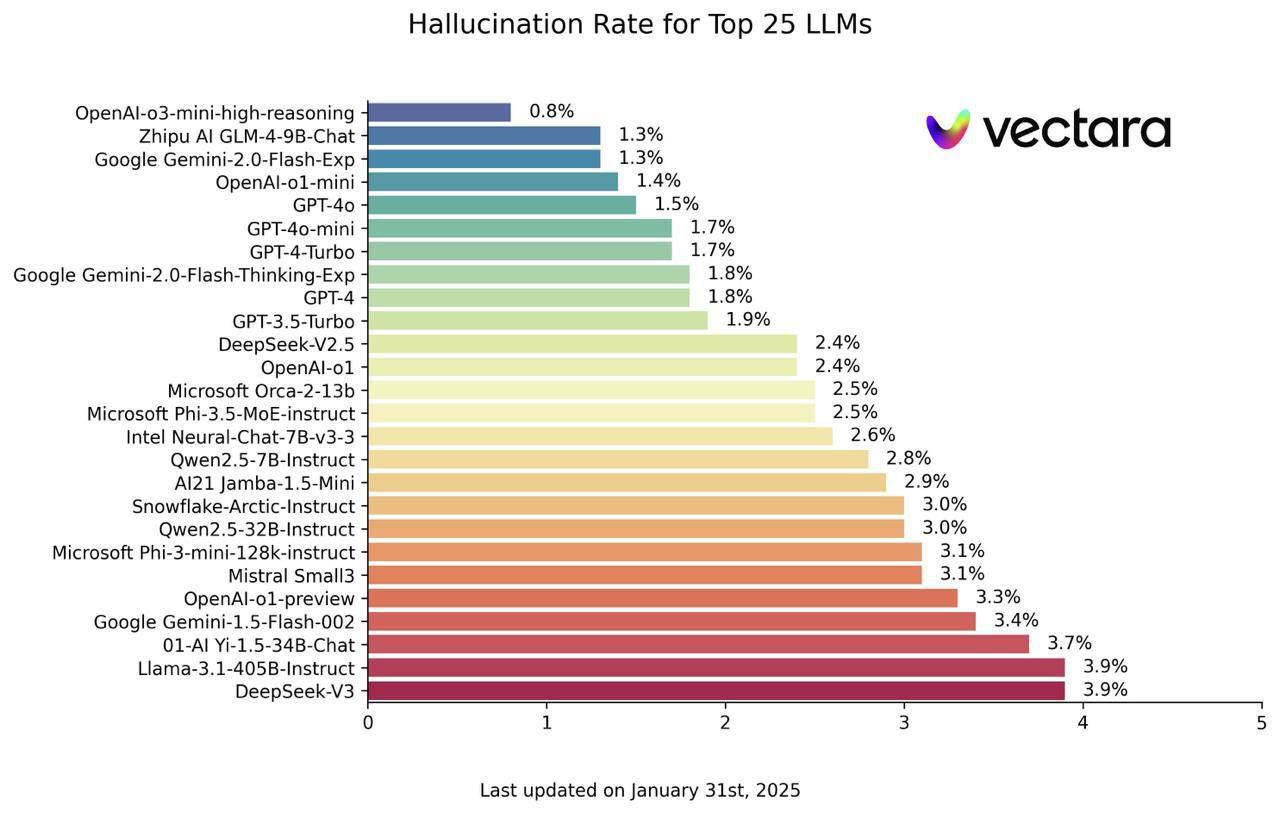
**o3-mini-high установила рекорд: 0,8% галлюцинаций - новый эталон для LLM!** Когда дело доходит до нейросетей, точность ключевая. И новая модель o3-mini-high просто разнесла конкурентов, показав исторический минимум ошибок - *всего 0,8% галлюцинаций*. **Сравнение гигантов: Кто ведет в гонке точности?** "LLM могут уверенно нести бред, придумывать факты, искажать данные и выдавать ложь за истину - и делают это так убедительно, что если вы не разбираетесь в теме, то даже не заподозрите подвох," - комментирует эксперт в области нейросетей. В этом контексте результаты o3-mini-high выглядят просто фантастически. Для сравнения: GPT-4o допускает ошибки в 1,5% случаев, DeepSeek-V3 - в 3,9%, o1 - в 2,4%. **Как оценивается процент галлюцинаций?** Эта метрика может звучать просто, но ее измерение - та еще задача. Известно, что часто нейросети оценивают друг друга, создавая эффект "эхо-каме
NeuroVesti
**o3-mini-high установила рекорд: 0,8% галлюцинаций - новый эталон для LLM!**
Когда дело доходит до нейросетей, точность ключевая. И новая модель o3-mini-high просто разнесла конкурентов, показав исторический минимум ошибок - *всего 0,8% галлюцинаций*.
**Сравнение гигантов: Кто ведет в гонке точности?**
"LLM могут уверенно нести бред, придумывать факты, искажать данные и выдавать ложь за истину - и делают это так убедительно, что если вы не разбираетесь в теме, то даже не заподозрите подвох," - комментирует эксперт в области нейросетей. В этом контексте результаты o3-mini-high выглядят просто фантастически.
Для сравнения: GPT-4o допускает ошибки в 1,5% случаев, DeepSeek-V3 - в 3,9%, o1 - в 2,4%.
**Как оценивается процент галлюцинаций?**
Эта метрика может звучать просто, но ее измерение - та еще задача. Известно, что часто нейросети оценивают друг друга, создавая эффект "эхо-каме
**o3-mini-high установила рекорд: 0,8% галлюцинаций - новый эталон для LLM!**
Когда дело доходит до нейросетей, точность ключевая. И новая модель o3-mini-high просто разнесла конкурентов, показав исторический минимум ошибок - *всего 0,8% галлюцинаций*.
**Сравнение гигантов: Кто ведет в гонке точности?**
"LLM могут уверенно нести бред, придумывать факты, искажать данные и выдавать ложь за истину - и делают это так убедительно, что если вы не разбираетесь в теме, то даже не заподозрите подвох," - комментирует эксперт в области нейросетей. В этом контексте результаты o3-mini-high выглядят просто фантастически.
Для сравнения: GPT-4o допускает ошибки в 1,5% случаев, DeepSeek-V3 - в 3,9%, o1 - в 2,4%.
**Как оценивается процент галлюцинаций?**
Эта метрика может звучать просто, но ее измерение - та еще задача. Известно, что часто нейросети оценивают друг друга, создавая эффект "эхо-каме
Дата публикации: 09.02.2025 06:02